模态覆盖
结构像、功能像、扩散像、EEG 以及多模态整合任务。
NeuroBench
NeuroBench 用于评估端到端神经影像工作流、复现准备度以及技能驱动执行能力,目前已覆盖数据处理与模型训练/评估。
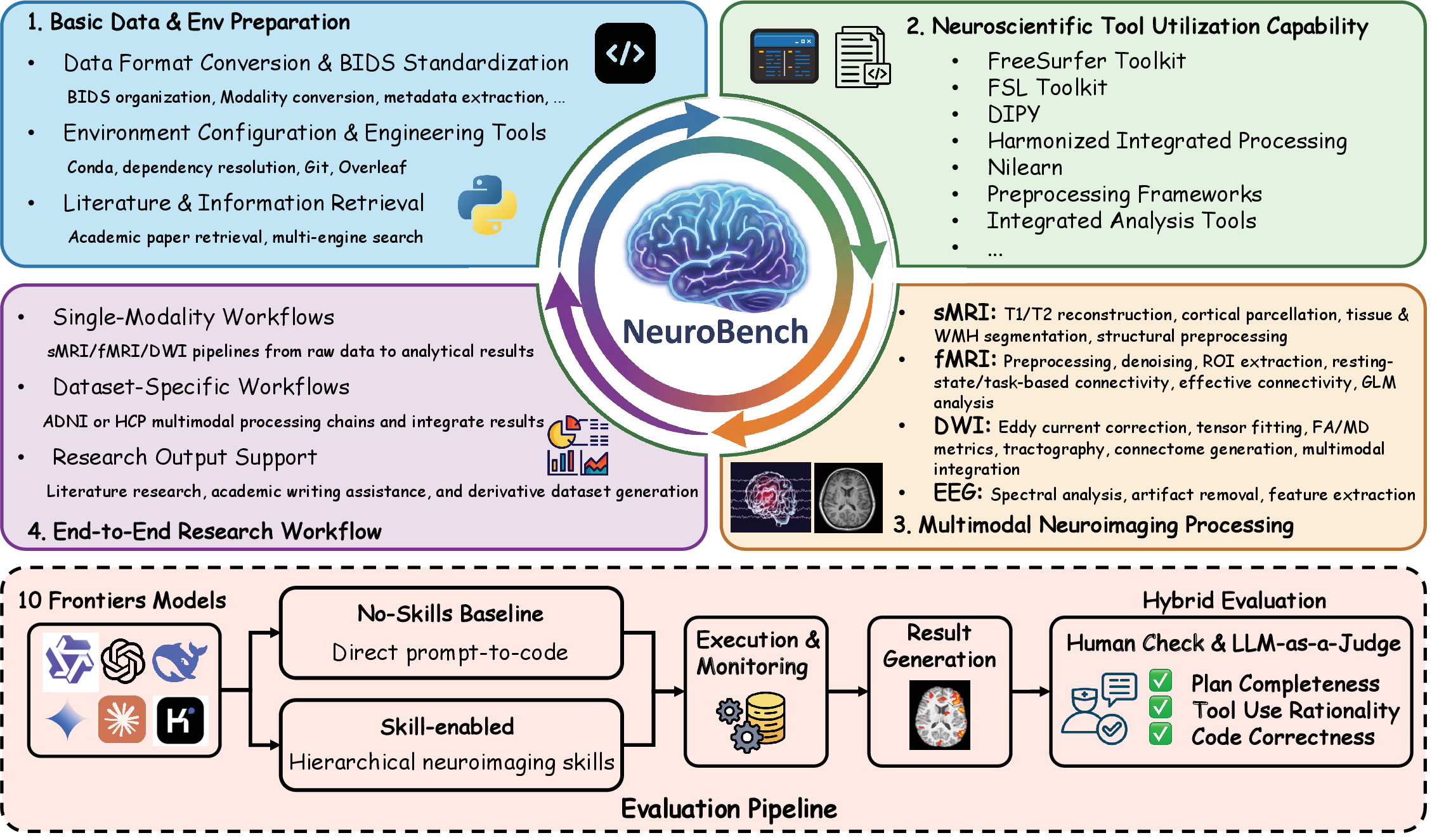
共 120 个任务(T01-T120),划分为七个类别。完整任务到类别的映射记录在 neurobench/task_atlas.json。
| 类别 | 数量 | 评测内容 |
|---|---|---|
| 数据编排 | 7 | BIDS 组织、数据集准备、格式转换(DICOM->NIfTI、下载) |
| 单工具执行 | 68 | 单工具调用 - DIPY 指标、FSL 提取、FreeSurfer 命令、Nilearn 函数等 |
| 多步流水线 | 19 | 端到端流水线(fMRIPrep、HCP full、ADNI end-to-end、多模态 full) |
| 开发环境 | 4 | Conda 环境、git 工作流、依赖规划、Overleaf 工具 |
| 研究工具 | 2 | 文献检索、多引擎检索 |
| 模型训练与评估 | 17 | 在统一的 HCP-age + ABIDE-dx 设置下训练和评估单个脑模型(FC / ROI 时间序列 / voxel) |
| 跨模型与跨数据集评估 | 3 | 多 atlas sweep、带 harmonization 的跨数据集泛化、site-stratified vs leave-site-out |
结构像、功能像、扩散像、EEG 以及多模态整合任务。
规划质量、工具/技能使用合理性、命令与代码正确性、复现准备度。
每个任务目录都包含一个 task.md 指令文件,明确输入、输出和检查项。
Benchmark 运行
NeuroBench 支持基线运行和技能增强运行,可以在 Web UI 或命令行批量执行。
with-skills:使用 skills/ 中加载的技能。no-skills:不使用技能的基线运行。--benchmark-compare-skills:对同一任务同时运行两种版本。output/。# Web benchmark 模式
python core/agent/main.py --web --benchmark
# CLI benchmark 批量运行
python core/agent/main.py --benchmark
# CLI 下的技能对照
python core/agent/main.py --benchmark --benchmark-compare-skills
使用 --score-benchmark 可以对 output/ 中已有报告进行打分,评分规则基于 GPT-5.4 的加权 rubric。
python core/agent/main.py --score-benchmark
python core/agent/main.py --score-benchmark --score-workers 8每个基础模型都会在 with-skills(在 NeuroClaw 框架下运行)与 no-skills 两种设置下进行评测。下图左侧为整体 benchmark 分数,右侧为 with-skills 下分数与 token 消耗的权衡。
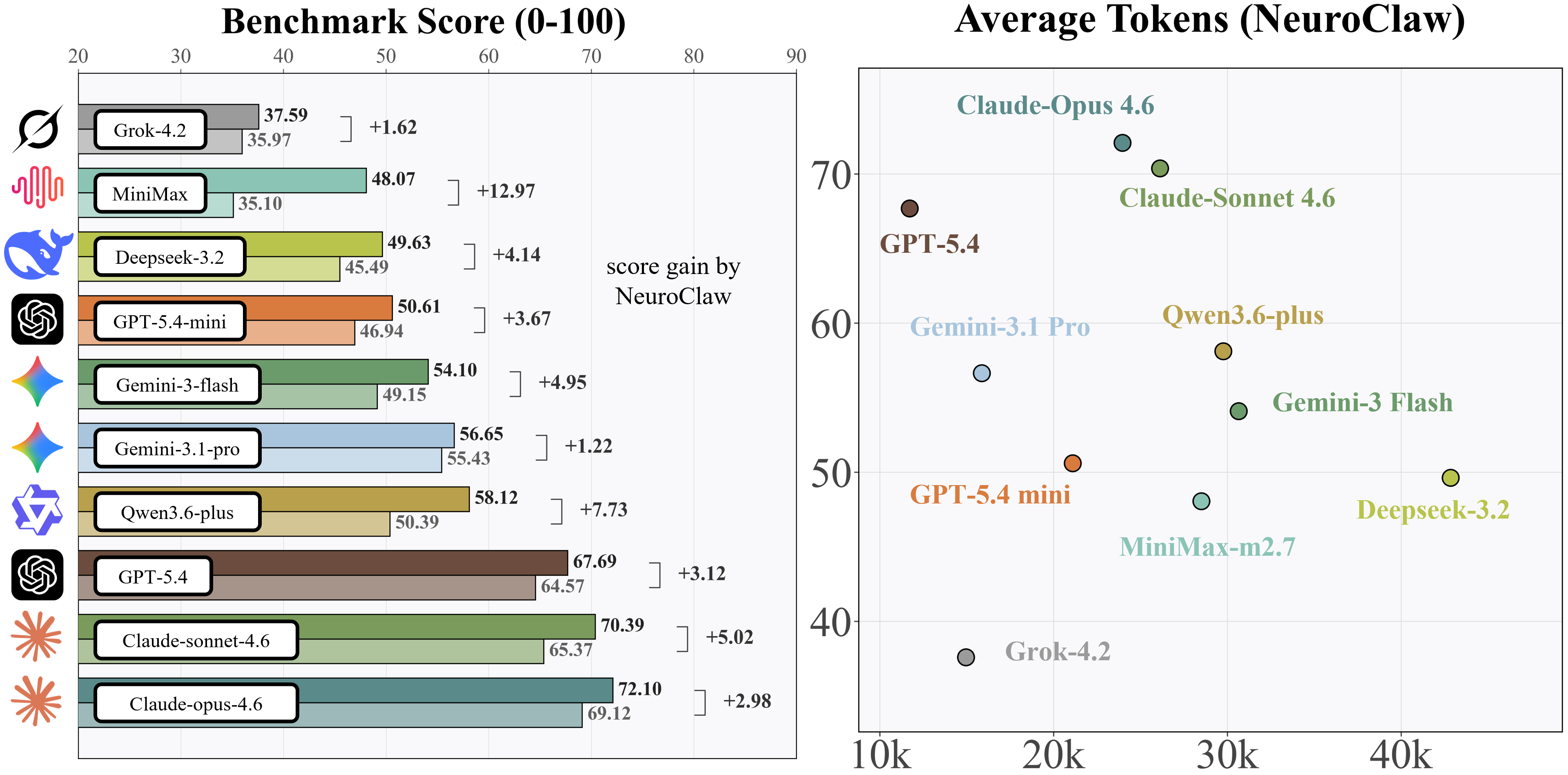
Aabs 表示相对 no-skills 基线的绝对分数提升;g 是归一化增益(裁剪到 [-1, 1])。
| 基础模型 | With Skills (%) | No Skills (%) | Aabs (%) | g |
|---|---|---|---|---|
| Claude-Opus-4.6 | 72.10 | 69.12 | 2.98 | 0.0965 |
| Claude-Sonnet-4.6 | 70.39 | 65.37 | 5.02 | 0.1450 |
| DeepSeek-3.2 | 49.63 | 45.49 | 4.14 | 0.0759 |
| Gemini-3-Flash | 54.10 | 49.15 | 4.95 | 0.0973 |
| Gemini-3.1-Pro | 56.65 | 55.43 | 1.22 | 0.0274 |
| GPT-5.4 | 67.69 | 64.57 | 3.12 | 0.0881 |
| GPT-5.4-mini | 50.61 | 46.94 | 3.67 | 0.0692 |
| Grok-4.2 | 37.59 | 35.97 | 1.62 | 0.0253 |
| MiniMax-M2.7 | 48.07 | 35.10 | 12.97 | 0.1998 |
| Qwen3-plus | 58.12 | 50.39 | 7.73 | 0.1558 |
所有 10 个基础模型在 NeuroClaw 框架下都有提升,平均绝对增益为 4.74 分。相对增益最大的是 MiniMax-M2.7(g = 0.1998)、Qwen3-plus(g = 0.1558)和 Claude-Sonnet-4.6(g = 0.1450)。
先跑任务,再对生成的报告打分,用于分析质量与效率。