ModAlign: Harmonizing Multimodal Alignment via Information-theoretic Conditional Dependencies
Abstract
Developing systems that interpret diverse real-world signals remains a fundamental challenge in multimodal learning. Current approaches face significant obstacles from inherent modal heterogeneity. While existing methods attempt to enhance fusion through cross-modal alignment or interaction mechanisms, they often struggle to balance effective integration with preserving modality-specific information.
We introduce ModAlign, a novel framework grounded in conditional information maximization principles addressing these limitations. Our approach reframes multimodal fusion through two key innovations: (i) we formulate fusion as conditional mutual information optimization with integrated protective margin that simultaneously encourages cross-modal information sharing while safeguarding against over-fusion eliminating modal characteristics; and (ii) we enable fine-grained contextual fusion by leveraging modality-specific conditions to guide integration.
Extensive evaluations across benchmarks demonstrate that ModAlign consistently outperforms state-of-the-art multimodal architectures, establishing a principled approach that better captures complementary information across input signals.
Motivation
A core challenge in multimodal learning is navigating the inherent trade-off between fusing information from different modalities (fusibility) and preserving their unique, complementary characteristics. As shown below, aggressively merging modalities can diminish their individual strengths. Furthermore, the importance of each modality can vary significantly depending on the context. Our work introduces a principled, information-theoretic approach to balance this trade-off, ensuring that fusion is both effective and context-aware, thereby preventing the loss of critical modality-specific information.
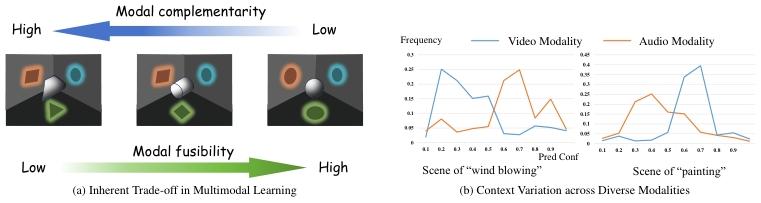
Key Contributions
We introduce ModAlign, a novel framework addressing the fundamental trade-off between modal complementarity and fusibility through conditional cross-modal information maximization with protective margins preserving modality-specific characteristics while enabling fusion.
We propose a context-aware fusion mechanism leveraging modality-specific conditions to guide fine-grained integration, demonstrating how contextual priors enhance multimodal learning by adapting to modal relationships across scenarios.
Comprehensive experiments across diverse benchmarks and modalities validate our method's superiority compared to existing ones, establishing a principled information-theoretic foundation for multimodal learning.
Method Overview
ModAlign is based on maximizing conditional mutual information (CMI) between modality-specific representations under a context condition. Our method not only boosts the alignment of shared information across modalities, but also regulates the excessive fusion by imposing a protective margin.
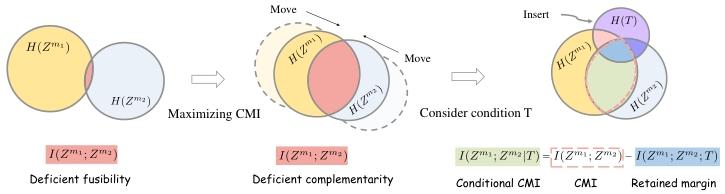
Notation & Problem Setup
Assume we have a training dataset D = {{x[n](m)}m=1M, y[n]}n=1N, where x[n](m) denotes the mth modality input of sample n and y[n] is the corresponding label. For each modality m, a unimodal encoder Fψ(m): X(m) → Z(m) with parameters ψ(m) produces a representation zm. The fusion operator Eh: {Z(m)}m=1M → Ẑ integrates the unimodal embeddings, where h denotes a critic or estimator function used in the mutual information estimation. In addition, let T denote an auxiliary context (e.g., category information) relevant to the modalities. Such a condition T is later incorporated to derive conditional cross-modal information bounds.
Noise-Contrastive Objective and Mutual Information Bound
To encourage cross-modal alignment while preventing over-fusion, we employ a conditional noise-contrastive estimation (NCE) strategy that incorporates context information. Our approach differs from standard NCE by introducing a conditional variable T that provides task-relevant guidance for the alignment process.
Definition of Positive and Negative Pairs
We first clarify the construction of training pairs: Positive pairs (zm1, zm2) are those where both representations are derived from the same sample, thus following the joint distribution p(zm1, zm2 | T). Negative pairs (zm1, zm2) are those where representations come from different samples, thus following the product of marginals p(zm1 | T) · p(zm2 | T). Let J ∈ {0,1} be a binary indicator where J=1 denotes positive pairs and J=0 denotes negative pairs. We use N1 to denote the number of positive pairs and N0 for negative pairs in our contrastive learning setup.
NCE Objective with Context
Given the context condition T, we define our conditional NCE loss. The critic function h: Zm1 × Zm2 × T → [0,1] estimates the probability that a pair (zm1, zm2) is positive given context T:
LNCE = E(zm1, zm2)∼ppos[log h(zm1, zm2, T)] + (N0/N1) E(zm1, zm2)∼pneg[log (1−h(zm1, zm2, T))] + (N0/N1) E(zm1, zm2)∼ppos[log h(zm1, zm2, T)]
where ppos represents positive pairs and pneg represents negative pairs. This formulation shows how positive and negative pairs contribute to learning. This posterior probability connects the classification task (distinguishing positive from negative pairs) to the information-theoretic objective of maximizing conditional mutual information. The term N0/N1 represents the ratio of negative to positive samples and serves as implicit regularization.
Algorithm 1: Multimodal Learning with ModAlign Strategy
Require: Context condition T, weighting coefficient α,
initial unimodal parameters ψ(m1) ∈ Ψ(m1), ψ(m2) ∈
Ψ(m2), classifier parameters w ∈ W, training data D = {{x(m)[n]}M m=1, y[n]}N n=1, and NCE estimator h ∈ H.
0: for i = 1, 2, . . . , I do
0: Sample mini-batch Bi from D;
0: Forward pass through unimodal encoders to obtain
{zm1, zm2};
0: Compute task loss LT ask (e.g., cross-entropy);
0: Eq. (1); Compute the conditional NCE loss LNCE(h) using
0: Update h by maximizing LNCE(h) via Eq. (7);
0: Update ψ(m1), ψ(m2) and w using the gradient of the
overall loss in Eq. (10);
0: end for
Experimental Results
Experimental Setup
We evaluate ModAlign on four diverse multimodal datasets: CREMA-D (audio-visual emotion recognition), AVE (audio-visual event localization), UPMC Food-101 (image-text classification), and GBMLGG (genomic-pathological data fusion). For CREMA-D and AVE, we use ResNet18 for feature extraction. For UPMC Food-101, we employ ViT-B/16 for images and BERT-base for text. For GBMLGG, we use ResNet-50 for pathological images and a sparse neural network for genomic profiles.
Comparisons with State-of-the-Arts
We compare ModAlign against several strong baselines including Joint-Train, InfoNCE, MMPareto, D&R, ReconBoost, OGM-GE, and PMR. The results demonstrate that ModAlign consistently outperforms all compared methods across all datasets.
| Methods | CREMA-D | AVE | Food-101 | GBMLGG |
|---|---|---|---|---|
| Unimodal [15] | 54.40 | 62.10 | 68.92 | 85.24 |
| Joint-Train [61] | 53.20 | 65.40 | 78.69 | 85.88 |
| InfoNCE [45] | 60.61 | 67.52 | 82.55 | 90.67 |
| MMPareto [54] | 60.12 | 67.42 | 82.31 | 90.25 |
| D&R [35] | 61.35 | 67.48 | 83.36 | 90.44 |
| ReconBoost [10] | 61.59 | 68.05 | 83.26 | 89.88 |
| OGM-GE [48] | 61.16 | 67.01 | 80.25 | 89.22 |
| PMR [17] | 61.10 | 67.10 | 82.09 | 89.06 |
| ModAlign (Ours) | 62.85 | 68.19 | 84.03 | 92.15 |
Ablation Studies
We conduct ablation studies to assess the contribution of each component in ModAlign. The full model achieves the best performance, confirming that each ingredient (conditional mutual information objective, protective margin term, context-aware prior, and semantic context) contributes to multimodal learning.
| Methods | CREMA-D | AVE | Food-101 | GBMLGG |
|---|---|---|---|---|
| W/o CMI Objective | 56.81 | 65.12 | 80.85 | 87.70 |
| W/o Protective Margin | 58.52 | 66.21 | 81.59 | 87.79 |
| W/o Context-aware Prior | 60.61 | 67.03 | 82.00 | 89.00 |
| W/o Semantic Context | 61.58 | 67.52 | 82.55 | 90.67 |
| ModAlign (Full) | 62.85 | 68.19 | 84.03 | 91.15 |